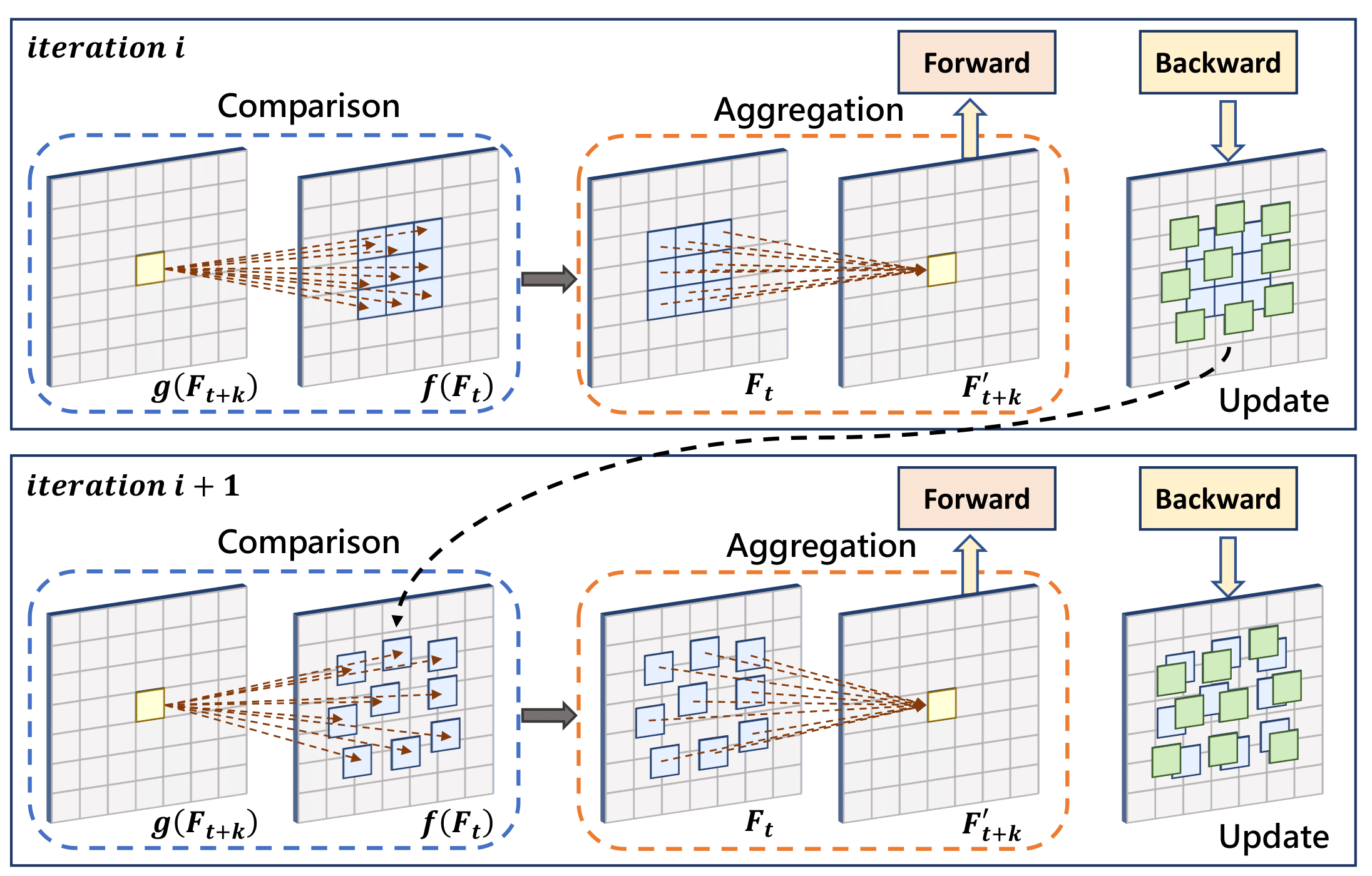
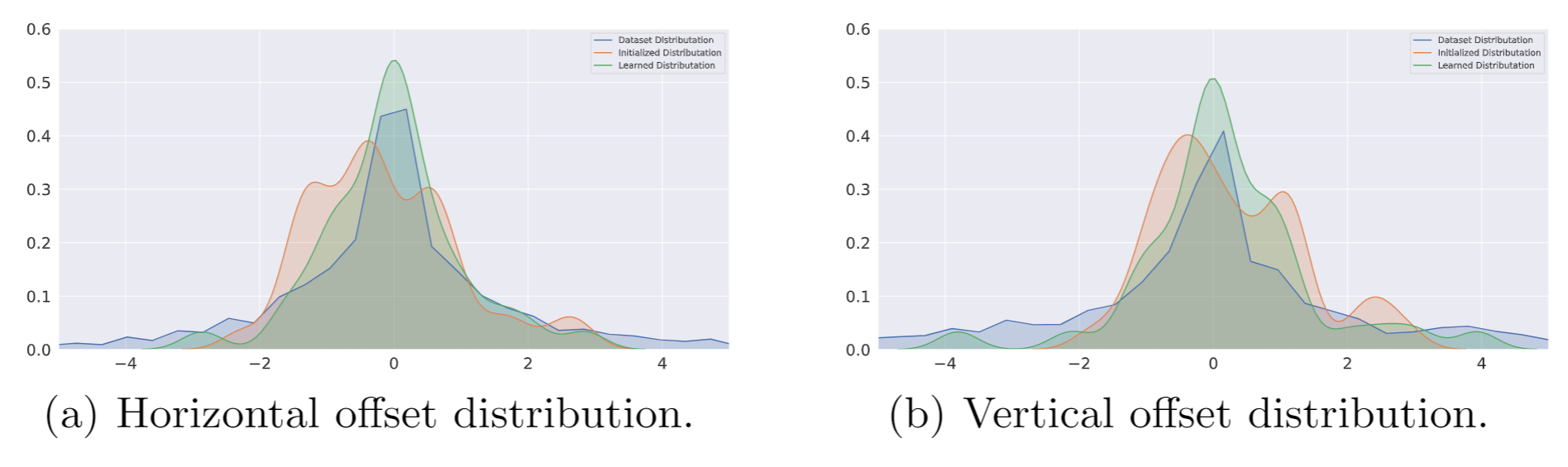
Learning Where to Focus for Efficient Video Object Detection
1National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences,
2School of Artificial Intelligence, University of Chinese Academy of Sciences,
3The Chinese University of Hong Kong, 4Horizon Robotics
3The Chinese University of Hong Kong, 4Horizon Robotics